ABOUT THE PROJECT
E2Data aims to answer two key questions:
How can we improve execution times while using less hardware resources?
In order to address the alarming scalability concerns raised in recent years, end users and cloud infrastructure vendors (such as Google, Microsoft, Amazon, and Alibaba) are investing in heterogeneous hardware resources, making available a diverse selection of architectures such as CPUs, GPUs, FPGAs, and MICs. The aim is to further increase performance while minimizing operational costs. Furthermore, besides current investments in heterogeneous resources, large companies such as Google have developed in-house ASICs with TensorFlow being the prime example.
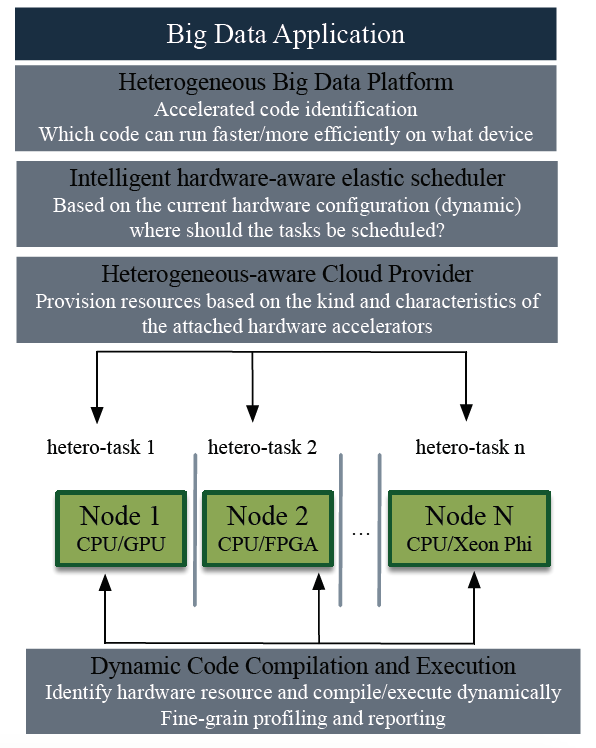
E2Data will provide a new Big Data software paradigm for achieving maximum resource utilization for heterogeneous cloud deployments without requiring developers to change their code. The proposed solution takes a cross-layer approach by allowing vertical communication between the four key layers of Big Data deployments: application, Big Data software, scheduler/cloud provider, and execution run time.
Enabling dynamic heterogeneous compilation of arbitrary code;
Following a full-stack vertical approach by enhancing state-of-the-art Big Data frameworks
Designing an intelligent elastic system which makes it possible to:
Profile results, communicate to scheduler, and assess decisions
Fall back and recompile on-the-fly;
Iterate until the AI enabled scheduler finds the “best” possible execution configuration.
How can the user establish for each particular business scenario which is the highest performing and cheapest hardware configuration?
The E2Data consortium brings together two groups of EU Big Data practitioners to achieve its ambitious goals.
The following four industry partners bring well-defined performance requirements and infrastructure constraints to the project:
The following members are subject matter experts and researchers from the following institutions:
DFKI, the creators of Apache Flink (the number one European competitor of Apache Spark), will provide solutions in the core of the Big Data stack,
ICCS will deliver a novel Big Data scheduler (i.e. the component that assigns hardware resources to tasks during execution) capable of intelligent resource selection,
UNIMAN with expertise in heterogeneous computing will work at the system level and enable dynamic code compilation and execution on diverse heterogeneous hardware resources, and
Kaleao will showcase that its high-performing, low-power, cloud architecture can strengthen EU’s Big Data hardware capabilities with E2Data’s proposed technologies.
These experts are responsible for actually implementing the E2Data solution. They do this by extending existing European open-source projects and leveraging the results of their research at the bleeding edge of the field.